本文为《推荐系统》蒋凡 译这本书的学习笔记,书本链接,提取密码:cm77。
第一章 引言
本章主要是介绍了一些推荐系统的背景和基本概念以及简要的介绍了下本书的结构。
1.1 协同过滤推荐
协同过滤推荐的思想主要是如果用户在过去有相同的偏好,那么他们在未来也会有相同的偏好。其任务主要是从大量候选集合中推荐出最有可能感兴趣的物品,而且用户是在隐式的与他人协作,因此这种技术也别称为协同过滤(CF,Collaborative Filtering)。
而在协同过滤的推荐场景中,常见的问题如下:
- 如何发现与目标用户有着相似兴趣的用户?
- 相似度怎么衡量?
- 新用户如何处理?(因为没有相关的购物记录或者行为记录)
- 如果只有很少的评分怎么处理?
- 除了利用相似的之外,还可以使用什么样的技术方式来判定用户是否会喜欢这个物品?
纯粹的协同过滤是不需要使用到有关物品的任何知识,更多的应该是一种集体智慧的体现吧!
1.2 基于内容的推荐
一般而言,推荐系统有两个目的:激发用户去做某件事情和解决信息过载。其实在流程上是分为召回和排序的,召回是筛选出用户感兴趣的集合主要是用于解决第一个目的,排序主要是解决信息过载问题。
基于内容推荐的核心主要是能够获取物品的描述(不管是人工生成的还是自动抽取的)和这些特征记录的重要记录,同时也需要抽取用户的特征,用户特征的获取主要可以分析用户的行为和反馈,或者询问用户的兴趣和偏好。
基于内容的推荐一般会面临以下几个问题:
- 系统如何自动获取并持续改进用户记录?
- 如何决定哪个物品匹配或者至少能接近、符合用户兴趣?
- 在对物品描述进行抽取的过程中,如何减少人工标注?
不过基于内容的推荐也有以下优点:
- 不需要大量用户就可以达到适度的推荐精度
- 一旦得到物品的属性就立即能推荐新的物品
1.3 基于知识的推荐
基于知识的推荐是利用额外的因果知识生成推荐,在这种基于知识的方法中,推荐系统通常会用到有关当前用户和有效物品的额外信息(这些信息一般都是人工提供的)。基于知识推荐一般会面临以下几个问题:
- 哪些知识能够生成知识库
- 什么机制可根据用户的特点来选择和物品排名
- 在没有购买记录的领域中如何获取用户信息?如何处理用户直接给到的偏好信息?
- 交互方式如何选择?
- 设计对话获取信息时,考虑哪些个性化信息能够准确的捕捉到用户的偏好信息?
1.4 混合推荐方法
混合推荐方法就是组合不同的技术产生更好或者更精确的推荐。在使用混合推荐的方法中一般面临以下几个问题:
- 那些方法能被组合,特定组合的前提是什么?
- 两个或多个推荐算法应该是顺序计算还是其他的混合方式
- 不同方法的结果对应权重如何确定?能否动态决定?
1.5 推荐系统的解释
解释主要是为了让用户更容易理解推荐系统的推理脉络,后续章节中推荐系统的解释主要是围绕解释协同过滤结果来解释以下问题:
- 推荐系统在解释其推荐结果的同时如何提高用户对系统的信任度?
- 推荐策略如何影响解释推荐的方式?
- 能通过解释让用户相信系统给出的建议是“公正的”或者不偏颇的么?
1.6 评估推荐系统
推荐系统研究的主要动力就是提高推荐质量,但是随之而来的我们如何衡量或者量化这些指标。在后面的章节中将围绕实验、半实验和非实验进行研究,一般会面临如下几个问题:
- 哪些研究设计适用于评估推荐系统
- 如何利用历史数据实验评估推荐系统
- 什么衡量标准适合不同的评估目标
- 现有的评估技术局限是什么?特别是在推荐系统的会话性和商业性价值而言
第二章 协同过滤推荐
协同过滤推荐方法的主要思想是利用已有用户群体的过去的行为或意见预测当前用户最可能喜欢哪些东西或者对哪些东西感兴趣。这么多年来,人们提出了各种算法和技术并在实际环境和人工测试环节得到了有效的验证。
纯粹的协同过滤方法输入只有给定的 用户-物品 评分矩阵,输出一般有以下几种类型:
- 表示当前用户对物品喜欢或不喜欢的程度的预测值
- n项推荐物品的列表,其中topN不包含用户已经购买的物品。
2.1 基于用户的最近邻推荐
基于用户的最近邻推荐的主要思想是:给定一个评分集和当前的活跃用户id,找出与当前用户过去有相同偏好的用户,这些用户被称为最近邻或者对等用户。然后对于对当前用户没见过的产品P,利用最近邻的评分进行估算。不过这种方法前提是基于一种假设的:
- 如果用户过去有相似的偏好,那么他们未来也会有相同的偏好
- 用户偏好不会随着时间变化
接下来我们用一组实例来具体介绍基于用户的最近邻推荐,下图为一个评分表,展示了Alice和其他用户的评分数据。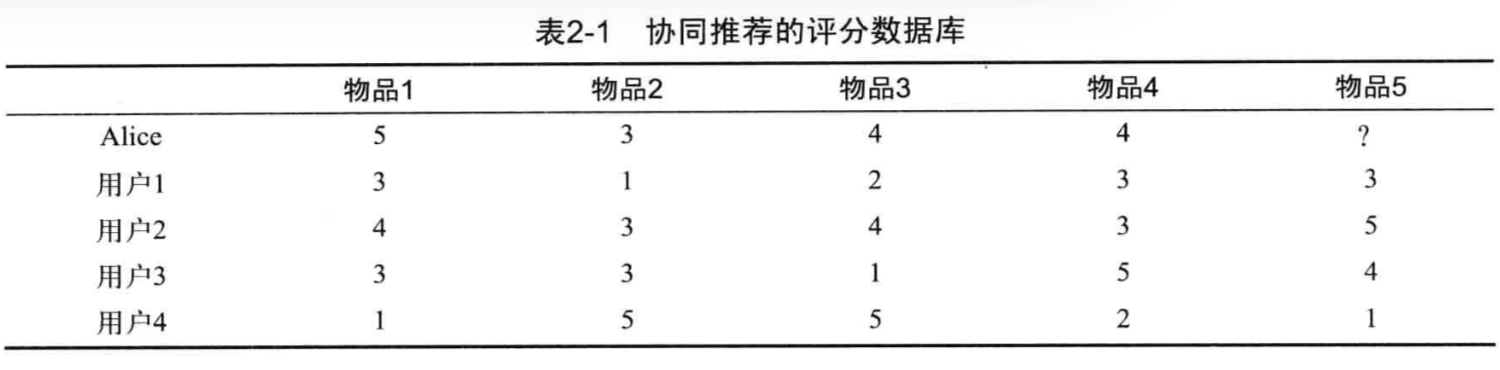
依据以上的评分数据集,我们想预测出Alice对物品5的评分。在计算评分之前,先介绍相关的符号:
- 用户集:$U={u_{1},u_{2},……,u_{n}}$
- 物品集:$P={p_{1},p_{2},……,p_{m}}$
- 评分矩阵:R代表评分项$r_{ij}$的评分矩阵,其中$i \in 1….n$,$j \in 1……m$
- 分值定义:从1(非常不喜欢)到5(非常喜欢)
如何确定相似用户集,推荐系统中通用的方法是Pearon相关系数,给定评分矩阵R,计算用户a和用户b的相似度sim(a,b)公式如下:
$$
sim(a,b)=\frac{\sum_{p \in P}(r_{a,p}-\hat{r}_{a})(r_{b,p}-\hat{r}_{b})}{\sqrt{\sum_{p \in P}(r_{a,p}-\hat{r}_{a})^2} \sqrt{\sum_{p \in P}(r_{b,p}-\hat{r}_{b})^2}}
$$
上述式子中$r_{a,p}$和$r_{b,p}$为用户对同一个物品的评分,$\hat{r}_{a}$和$\hat{r}_{b}$为用户的平均评分。
计算Alice和用户1的相似度($\hat{r}_{Alice}=\hat{r}_{a}=4$,$\hat{r}_{user1}=\hat{r}_{b}=2.4$)
$$
sim(a,b)=\frac{(5-\hat{r}_{a})(3-\hat{r}_{b})+(3-\hat{r}_{a})(1-\hat{r}_{b})+…+(4-\hat{r}_{a})(3-\hat{r}_{b})}{\sqrt{(5-\hat{r}_{a})^2+(3-\hat{r}_{a})^2+…}\sqrt{(3-\hat{r}_{b})^2+(1-\hat{r}_{b})+…}}=0.85
$$
Pearson相关系数取值从1(强正相关)到-1(强负相关)。Alice和其他用户,即用户2、用户3和用户4的相似度分别为:0.70,0.00,-0.79。
从以上可以看出用户1和用户2的历史评分和Alice相近,同时也看到了用户4和Alice的一个差异性。为了预测物品5的评分,我们需要考虑哪些近邻的的评分应该被重视以及如何评价他们的评分,以下公式给给出了最相似的N个近邻与用户a平均评分$\hat{r}_{a}$的偏差,计算用户a对物品p的预测值:
$$
pred(a,p)=\hat{r}_{a}+\frac{\sum_{b \in N}sim(a,b)(r_{b,p}-\hat{r}_{b})}{\sum_{b \in N}sim(a,b)}
$$
则依据用户1和用户2测算Alice度物品5的评分:
$$
pred(Alice,物品5)=4+\frac{0.85*(3-2.4)+0.70*(5-3.8)}{0.85+0.7}=4.87
$$
通过以上的计算我们大致了解到了,计算评分我们首先要确定用户的相似度、当前用的近邻N以及近邻用户评分如何赋权。
- 用户相似度 :上述例子中我们采用的是Pearson相关系数,根据文献的调研情况而言 改进余弦相似度、Spearman相关系数 或 均方差 等其他方法也能用于计算用户相似度。
- 赋权体系 :因为许多领域存在一些所有人都喜欢的物品,让两个用户对有争议的物品打成共识会比对广受欢迎的物品达成共识更有价值。为了解决这个问题,Breese et al(1998)提出对物品评分进行变换,降低对广受欢迎的物品有相同看法的相对重要性。类似于信息检索的idf值的概念提出 反用户频率(iuf) 。同时 方差权重因子 也解决了同样的问题。
- 选择近邻 :为了避免对计算时间造成负面影响我们不必考虑所有的近邻,我们只包含了所有的与当前用户正相关的用户。但是有时候正相关的用户集合太多,为了降低近邻的规模我们可以直接设定一个阈值或者将规模限定为一个值。近邻个数K的选择太大太小都不好,在大多数情况下20~50个比较合理。
2.2 基于物品的最近邻推荐
基于用的的最近邻推荐已经成功应用在不同领域,但是随着用户和物品的日益增多带来了很多严峻的挑战。尤其是当需要扫描大量潜在的近邻时候很难做到实时预测。因此大型电子商务网站会采用 基于物品的最近邻推荐。这种方法非常适合做离线计算,因此在评分矩阵非常大的时候也能做到实时推荐。基于物品的算法主要思想是利用物品的相似度而不是用户间相似度来计算预测值。
在基于物品的推荐方法中,余弦相似度由于效果精确已经被证实是一种标准的度量体系。两个物品a和b对应的评分向量用$\vec{a}$和$\vec{a}$来表示,其相似度定义如下:
$$
sim(a,b)=\frac{\vec{a} \cdot \vec{b}}{|\vec{a}| * |\vec{b}| }
$$
符号$\cdot$表示向量的点积,$|\vec{a}|$表示向量的欧式长度,即向量自身点积的平方根。
依据上一小节的例子,物品5和物品1的评分向量分别为(3,5,4,1)和(3,4,3,1),其相似度计算如下:
$$
sim(I_{5},I_{1})=\frac{3*3+5*4+4*3+1*1}{\sqrt{3^2+5^2+4^2+1^2}*\sqrt{3^2+4^2+3^2+1^2}}=0.99
$$
相似度值介于0到1之间,越接近1则表示越相似。基本的余弦相似度不会考虑用户评分平均值之间的差异。改进版的余弦方法能够解决这个问题,做法是在评分值中减去平均值。相应的改进的余弦相似度的范围在-1和1之间,就像Pearson系数一样。
设U为所有同时给物品a和b评分的用户集,改进的余弦相似度如下:
$$
sim(a,b)=\frac{\sum_{u \in U}(r_{u,a}-\hat{u}_{a})(r_{u,b}-\hat{u}_{b})}{\sqrt{\sum_{u \in U}(r_{u,a}-\hat{u}_{a})^2}\sqrt{\sum_{u \in U}(r_{u,b}-\hat{u}_{b})^2}}
$$
因此我们可以对原始的评分数据集进行变换,使用 评分值-平均评分值 的偏差来替代,如下表所示: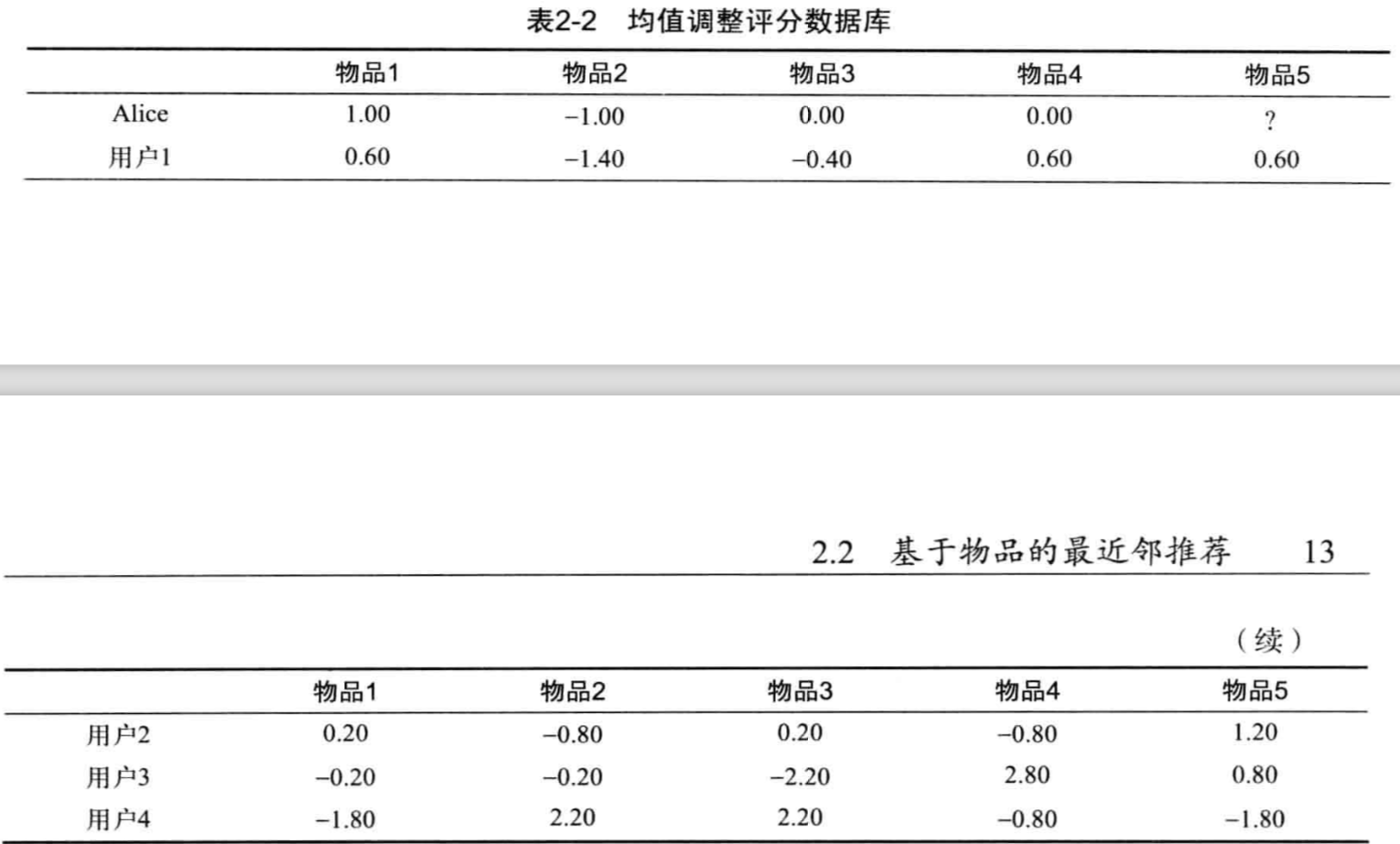
则物品5和物品1使用改进评分数据集的评分向量分别为(0.60,1.20,0.80,-1.80)和(0.60,0.20,-0.20,-1.80),则其改进余弦相似度为:
$$
\begin{split}
sim(I_{5},I_{1}){} &=\frac{0.60*0.60+1.20*0.20+0.80*(-0.20)+(-1.80)*(-1.80)}{\sqrt{0.60^2+1.20^2+0.80^2+1.80^2}*\sqrt{0.60^2+0.20^2+0.20^2+1.80^2}}\\
{} &=0.80
\end{split}
$$
确定物品的相似度之后,我们可以通过计算Alice对所有与物品5相似物品的加权评分总和来预测Alice对物品5的评分。形式上,我们预测用户u对物品p的评分为:
$$
pred(u,p)=\frac{\sum_{i \in relatedItems(u)}sim(i,p)* r_{u,i}}{\sum_{i \in relatedItems(a)}sim(i,p)}
$$
推荐要求线上环境必须在及其短的时间内返回结果时,当用户数量M达到几百万时,实时计算预测值仍然不可行。为了在不牺牲推荐精度的情况下人们通常选择离线事先计算好的 物品相似度矩阵 ,描述所有物品两两之间的相似度。在运行时候通过确定与p最相似的物品并计算u对这些物品评分的加权总和来得到用户u对物品p的预测评分。近邻数量受限于当前用户评分过的物品个数,这个一般都较少,所以预测值可以在很短的时间内完成计算。
原则上离线计算这个思路也可以在基于用户的近邻推荐中实现,但是在实际情况下两个用户的评分重叠的情况非常少见,相对而言物品相似度更稳定。
2.3 关于评分
关于评分分为隐式和显式评分。
显式评分一般是直接询问用户对物品的评分,但是其问题主要是在于需要用户额外的付出,而且用户很可能看不到好处而不愿意提供真实评分。因此会导致显式评分会非常稀疏且推荐质量并不高。
隐式评分主要是基于用的行为对物品进行评分,如当用户购买了一个物品就表示一个正向评分,很多推荐系统也会跟踪用户的浏览行为。尽管隐式评分不需要用户额外付出而且可以持续的筹集,但是用户的行为能否被正确的解释还是难以确定的。
第三章 基于内容的推荐
待添加……
第四章 基于知识的推荐
待添加……
第五章 混合推荐方法
待添加……
第六章 推荐系统的解释
待添加……
第七章 评估推荐系统
待添加……
第八章 案例分析:移动互联网个性化游戏推荐
待添加……