1、简介
TextRank算法的思想来源于google的PageRank算法,其主要是将文本分割成若干的组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序,仅仅利用单文档的信息就可以完成关键词抽取和信息摘要的任务。和LDA、HMM等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
2、PageRank
2.1、PageRank算法原理
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名。是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,自从Google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界十分关注的计算模型。
PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下:
- 在初始阶段:网页通过链接关系构建起Web图,每个页面设置相同的PageRank值,通过若干轮的计算,会得到每个页面所获得的最终PageRank值。随着每一轮的计算进行,网页当前的PageRank值会不断得到更新。
- 在一轮中更新页面PageRank得分的计算方法:在一轮更新页面PageRank得分的计算中,每个页面将其当前的PageRank值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值。而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的PageRank得分。当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
对于一个页面A,则他的PR值为:
$$
S(V_{i})=(1-d)+d* \sum_{V_{j} \in In(V_{i})}\frac{1}{|Out(V_{j})|}S(V_{j})
$$
在以上公式中:
- $S(V_i)$: 网页$V_i$的重要度(权重),初始值可设为1。
- $d$: 阻尼系数,一般为0.85。
- $In(V_i)$:能跳转到网页$V_i$的页面,在图中对应入度对应的点。
- $Out(V_j)$:网页$V_j$能够跳转到的页面,在图中对应出度的点。
另外一个版本的公式:
$$
S(V_{i})=\frac{(1-d)}{N}+d* \sum_{V_{j} \in In(V_{i})}\frac{1}{|Out(V_{j})|}S(V_{j}),其中N为页面总数
$$
2.2、具体实例
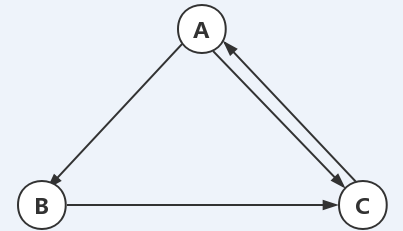
为了便于计算,我们假设每个页面的PR初始值为1,d为0.5。接下来我们针对每个节点计算对应的PageRank值:
- 页面A的PR值计算:
$$
PR(A)=0.5+0.5*PR(C)=0.5+0.5=1
$$ - 页面B的PR值计算:
$$
PR(B)=0.5+0.5*\Big(PR(A) \div 2\Big)=0.5+0.5 \cdot 0.5=0.75
$$ - 页面C的PR值计算:
$$
PR(C)=0.5+0.5*\Big(PR(A) \div 2 +PR(B)\Big)=0.5+0.5 \cdot (0.5+0.75)=1.125
$$
从以上的计算可以看出,每个节点投票只能投一次,但是由于其指向其他节点多了即节点的出度(C(T)),其对每个节点的投票需要加权,加权值为$\frac{1}{C(T)}$。在上述的计算过程中,节点A对B节点的投票值只有1/2的权重,因为A节点的出度为2。其他的依次类推。
入度表示每个节点被多少节点指向,其PR值为这些入度的路径的PR值求和。
下面是迭代计算12轮之后,各个页面的PR值: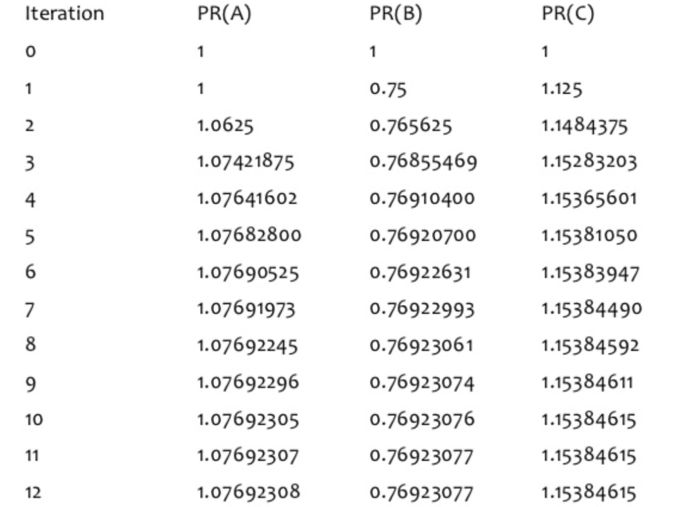
既然算法需要迭代训练,那么肯定需要知道什么时候收敛。所以一般需要设置收敛条件:比如上次迭代结果与本次迭代结果小于某个误差;比如还可以设置最大循环次数。
3、基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
- 把给定的文本T按照完整句子进行分割,即
- 对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中是保留后的候选关键词。
- 构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
- 根据上面公式,迭代传播各节点的权重,直至收敛。
- 对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
- 由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
4、基于TextRank的自动文摘
基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘。将每个句子看成图中的一个节点,若两个句子之间有相似性,认为对应的两个节点之间有一个无向有权边,权值是相似度,通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。其主要步骤如下:
- 预处理:将输入的文本或文本集的内容分割成句子得$T=[S_{1},S_{2},…..,S_{m}]$,构建图$G=(V,E)$其中V为句子集,对句子进行分词、去除停止词,得$S_{i}=[t_{i,1},t_{i,2},…….,t_{i,n}]$,其中$t_{i,j} \in S_{j}$是保留后的候选关键词。
句子相似度计算:构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子$S_{i},S_{j}$,采用如下公式进行计算:
$$
Similarity(S_{i},S_{j})=\frac{|{w_{k}|w_{k}\in S_{i} \cap w_{k}\in S_{j}}|}{log(|S_{i}|)+log(|S_{j}|)}
$$$S_i$:第i个句子。$w_k$:第k个单词。$|S_i|$:句子i中单词数。
简单来说就是,两个句子单词的交集除以两个句子的长度(至于为什么用log,没想明白,论文里也没提)。然后还有一点,就是,其他计算相似度的方法应该也是可行的,比如余弦相似度,最长公共子序列之类的,不过论文里一笔带过了。
若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值$w_{i,j}=Similarity(S_{i},S_{j})$句子权重计算:迭代传播权重计算各句子的得分,计算公式如下:
$$
WS(V_{i})=(1-d)+d* \sum_{V_{j} \in In(V_{i})}\frac{w_{ji}}{\sum_{V_{k} \in Out(V_{j})}w_{jk}}S(V_{j})
$$上面公式与PageRank中的公式相比而言,PageRank中的出度权重每条边的权重都是相等的,在上述公式中使用相似度来进行加权赋值,这样每条出度的边的权重就不一定一样了,而在PageRanK中是等权的。
抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
- 形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文摘
在上述生成自动摘要的过程中与PageRank不同的节点间是否产生边和边的权重是以句子相似度来决定的。在上述的过程中给出了原始的衡量句子相似度的方式。但是其实这部分我们可以使用各种方式来衡量句子的相似度,比如引入Sentence Embedding 然后计算cos距离,杰卡德距离等等。至于句子如何向量化方式就很多了,深度学习中的方法也很多,在此就不展开了。
5、结论
TextRank的思想主要来源于PageRank,而在PageRank中边的产生是由网页之间的相互连接来产生的,在TextRank中边的产生是由切分句子后窗口共现产生的(关键词抽取任务时)和句子相似度卡阈值产生的(自动文摘任务时)。对于边的权重而言,在自动文摘任务时候边是带权重的,每条边的出度权值不是等值的,在稳重的PageRank中是等值的,在关键词抽取的任务中出度值也是等值的。