1、使用timeline来优化优化性能
timeline可以分析整个模型在forward和backward的时候,每个操作消耗的时间,由此可以针对性的优化耗时的操作。
案例:我之前尝试使用tensorflow多卡来加速训练的时候, 最后发现多卡速度还不如单卡快,改用tf.data来 加速读图片还是很慢,最后使用timeline分析出了速度慢的原因,timeline的使用如下1
2
3
4
5
6
7
8
9
10run_metadata = tf.RunMetadata()
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
config = tf.ConfigProto(graph_options=tf.GraphOptions(
optimizer_options=tf.OptimizerOptions(opt_level=tf.OptimizerOptions.L0)))
with tf.Session(config=config) as sess:
c_np = sess.run(c,options=run_options,run_metadata=run_metadata)
tl = timeline.Timeline(run_metadata.step_stats)
ctf = tl.generate_chrome_trace_format()
with open('timeline.json','w') as wd:
wd.write(ctf)
然后到谷歌浏览器中打卡chrome://tracing 并导入 timeline.json ,最后可以看得如下图所示的每个操作消耗的时间,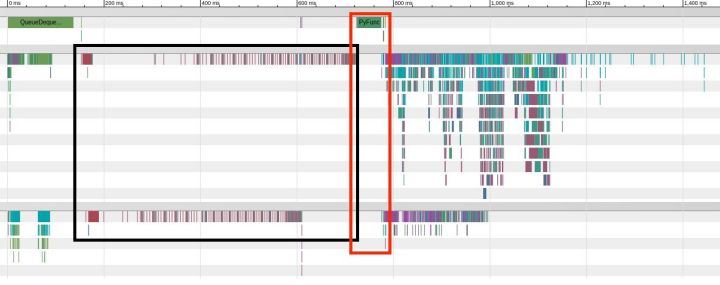
这里横坐标为时间,从左到右依次为模型一次完整的forward and backward过程中,每个操作分别在cpu,gpu 0, gpu 1上消耗的时间,这些操作可以放大,非常方便观察具体每个操作在哪一个设备上消耗多少时间。
这里我们cpu上主要有QueueDequeue操作,这是进行图片预期过程,这个时候gpu在并行计算的所以gpu没有空等;另外我的模型还有一个PyFunc在cpu上运行,如红框所示,此时gpu在等这个结果,没有任何操作运行,这个操作应该要优化的。另外就是如黑框所示,gpu上执行的时候有很大空隙,如黑框所示,这个导致gpu上的性能没有很好的利用起来,最后分析发现是我bn在多卡环境下没有使用正确,bn有一个参数updates_collections我设置为None 这时bn的参数mean,var是立即更新的,也是计算完当前layer的mean,var就更新,然后进行下一个layer的操作,这在单卡下没有问题的, 但是多卡情况下就会写等读的冲突,因为可能存在gpu0更新(写)mean但此时gpu1还没有计算到该层,所以gpu0就要等gpu1读完mean才能写,这样导致了 如黑框所示的空隙,这时只需将参数设置成updates_collections=tf.GraphKeys.UPDATE_OPS 即可,表示所以的bn参数更新由用户来显示指定更新,如1
2
3update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
2、使用tf.addchecknumerics_ops检查NaN
1 | check= tf.addchecknumerics_ops |
来检查NaN问题 ,该操作会报告所有出现NaN的操作,从而方便找到NaN的源头。
3、使用 tf.data API创建数据流
在比较 naive 的 feed_dict 工作流中,GPU 始终“坐冷板凳”,必须等 CPU 向它提供下个批次的数据。而在tf.data工作流中,能够以异步方式预读取下个批次的数据,从而使 GPU 的整体时间降到最小。我们还可以进一步通过将加载和预处理操作并行化来加快工作流的速度。
要想创建一个简单的数据工作流,你需要两个对象:
- tf.data.Dataset:存储你的数据集;
- tf.data.Iterator:从数据集中逐个提取数据项。
用于图像工作流中的 tf.data.Dataset 如下所示:1
2
3
4
5[
[Tensor(image), Tensor(label)],
[Tensor(image), Tensor(label)],
...
]
整个流程如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 来源
def load_image(path):
image_string = tf.read_file(path)
# 不要使用 tf.image.decode_image,不然输出的形状会不明确
image = tf.image.decode_jpeg(image_string, channels=3)
# 这会转换为 [0, 1]之间的浮点值
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize_images(image, [image_size, image_size])
return image
# 将函数load_image 应用到数据集中的每个文件名
dataset = dataset.map(load_image, num_parallel_calls=8)
接着使用tf.data.Dataset.batch()来创建批次:
# 每个批次创建64张图像
dataset = dataset.batch(64)
#buffer_size为GPU预读批次
dataset = dataset.prefetch(buffer_size=1)
#创建一个迭代器来迭代数据集
iterator = dataset.make_initializable_iterator()
#创建一个占位符向量
batch_of_images = iterator.get_next()
#会话
with tf.Session() as session:
for i in range(epochs):
session.run(iterator.initializer)
try:
# 迭代整个数据集
while True:
image_batch = session.run(batch_of_images)
except tf.errors.OutOfRangeError:
print('End of Epoch.')
Shuffle数据
使用 tf.data.Dataset.shuffle() 将文件名打乱(shuffle),指明元素数量的参数每次都应被打乱。总的来说,建议打乱整个列表。1
2dataset = tf.data.Dataset.from_tensor_slices(files)
dataset = dataset.shuffle(len(files))
标签
创建初始数据集时,将标签(或其它元数据)连同图像一起加载:1
2
3# 文件是一个图像文件名的Python列
# 标签是一个Numpy数组,包含每张图像的标签数据
dataset = tf.data.Dataset.from_tensor_slices((files, labels))
在应用到数据集的所有函数中一定要包含 .map(),让标签数据能够得以传递:1
2
3
4
5
6def load_image(path, label):
# 加载图像
return image, label
dataset = dataset.map(load_image)
3、多卡GPU设置
1 | import os |
4、限制CPU个数
1 | cpu_num = int(os.environ.get('CPU_NUM', 1)) |
5、word2vec的小技巧
经常搞各种乱七八糟的 word2vec ,以前笨的时候,要在非 tf 框架下映射好 id,然后写 pair,然后存文件训练,文件几百 G 的话,做起来炒鸡麻烦。。特么要天天这么搬砖累死人。其实 tf 高层抽象用得好,可以直接读文件,hash 映射,做 pair,一路写到 loss 不带眨眼,不到100行代码可以解决任意任意 csv 格式文件的 embedding 训练问题,还支持 hadoop 上读取,这就炒鸡方便了。
1 | import tensorflow as tf |