一、信息熵
根据香农(Shannon)给出的信息熵公式,对于任意一个随机变量X,它的信息熵定义如下,单位为比特(bit):
$$ H(X) = -\sum_{i=1}^{m}p(x_i)logp(x_i)$$
在物理界中熵是描述事物无序性的参数,熵越大则越混乱,类似的在信息论中熵表示随机变量的不确定程度。
下图描述了各种熵的关系: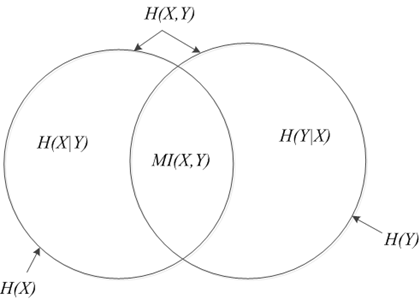
二、条件熵
设X,Y为两个随机变量,X的取值为 $x_1,x_2,…,x_m $ ,Y 的取值为$ y_1,y_2,…y_n $,则在X 已知的条件下Y的条件熵记做$H(Y|X)$:
$$
H(Y|X)=\sum_{i}^{m}P(Y|X=x_{i}) \\
=-\sum_{i=1}^{m}p(x_i)\sum_{j=1}^{n}p(y_{j}|x_{i})logp(y_{j}|x_{i}) \\
=-\sum_{i=1}^{m}\sum_{j=1}^{n}p(y_{j},x_{i})logp(y_{j}|x_{i}) \\
=-\sum_{x_{i},y_{j}}p(x_{i},y_{j})logp(y_{j}|x_{i})
$$
注意,这个条件熵,不是指在给定某个数(某个变量为某个值)的情况下,另一个变量的熵是多少,变量的不确定性是多少?而是期望!
因为条件熵中X也是一个变量,意思是在一个变量X的条件下(变量X的每个值都会取),另一个变量Y熵对X的期望。
三、联合熵
设X,Y为两个随机变量,X的取值为 $x_1,x_2,…,x_m $ ,Y 的取值为$ y_1,y_2,…y_n $,则其联合熵定义为:
$$H(X,Y)=-\sum_{i}^{m}\sum_{j}^{n}p(x_{i},y_{j})logp(x_{i},y_{j})$$
联合熵与条件熵的关系
$$
H(Y|X)=H(X,Y)-H(X) \\
H(X|Y)=H(X,Y)-H(Y)
$$
联合熵满足几个性质 :
- $H(Y|X)>=max(H(X),H(Y))$
- $H(Y|X)<=H(X)+H(Y)$
- $H(X,Y)>=0$
四、相对熵(KL散度)
相对熵,又称为KL距离,是Kullback-Leibler散度(Kullback-Leibler Divergence)的简称。它主要用于衡量相同事件空间里的两个概率分布的差异。其定义如下:
$$D(P||Q)=\sum_{x \in X}P(x)log\frac{P(X)}{Q(X)}$$
相对熵(KL-Divergence KL散度): 用来描述两个概率分布 P 和 Q 差异的一种方法。 它并不具有对称性,这就意味着:
$$D(P||Q) \neq D(Q||P)$$
KL 散度并不满足距离的概念,因为 KL 散度不是对称的,且不满足三角不等式。
对于两个完全相同的分布,他们的相对熵为0,$D(P||Q)$与函数P和函数Q之间的相似度成反比,可以通过最小化相对熵来使函数Q逼近函数P,也就是使得估计的分布函数接近真实的分布。KL可以用来做一些距离的度量工作,比如用来度量topic model得到的topic分布的相似性。
五、互信息(MI)
对于随机变量 X,Y 其互信息可表示为$MI(X,Y)$:
$$
MI(X,Y)=\sum_{i=1}^{m}\sum_{j=1}^{n}p(x_{i},y_{j})log_{2}\frac{p(x_{i},y_{j})}{p(x_{i})p(y_{j})}
$$
与联合熵分布的区别:
$$
H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y) \\
MI(X,Y)=H(X)−H(Y|X)=H(Y)−H(X|Y)
$$
六、点互信息(PMI)
可以看到使用PMI衡量两个变量之间的相关性,比如两个词,两个句子。原理公式为:
$$
PMI(x;y)=log\frac{p(x,y)}{p(x)p(y)}=log\frac{p(x|y)}{p(x)}=log\frac{p(y|x)}{p(y)}
$$
在概率论中,如果x和y无关,$p(x,y)=p(x)p(y)$;如果x和y越相关,$p(x,y)$和$p(x)p(y)$的比就越大。从后两个条件概率可能更好解释,在y出现的条件下x出现的概率除以单看x出现的概率,这个值越大表示x和y越相关。
log取自信息论中对概率的量化转换(对数结果为负,一般要再乘以-1,当然取绝对值也是一样的)
在自然语言处理中可以用于新词或新的短语发现。
七、交叉熵
设随机变量X的真实分布为p,用q分布来近似p ,则随机变量X的交叉熵定义为:
$$
H(p,q)=E_{p}[−logq]=−\sum_{i=1}^{m}p(x_{i})logq(x_{i})
$$
形式上可以理解为使用q来代替p求信息熵了。交叉熵用作损失函数时,q即为所求的模型,可以得到其与相对熵的关系:
$$
H(p,q)=-\sum_{x}p(x)logq(x) \\
=-\sum p(x)log\frac{q(x)}{p(x)}p(x) \\
=-\sum p(x)logp(x)-\sum_{x}p(x)log\frac{q(x)}{p(x)} \\
=H(p)+D(p||q)
$$
可见分布p与q的交叉熵等于p的熵加上p与q的KL距离,所以交叉熵越小,D(P||Q)越小,即分布q与p越接近,这也是相对熵的一个意义。
逻辑回归的损失函数:$J(\theta)=-[yln(h_{\theta}(x))+(1-y)ln(1-h_{\theta}(x))]$
softmax的交叉熵损失函数:$CrossEntropy=-\sum_{i=1}^{m}y_ilog(p_i)$
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
在特征工程中,可以用来衡量两个随机变量之间的相似度。
在语言模型中(NLP)中,由于真实的分布p是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。
八、信息增益及信息增益比
信息增益,是一种衡量样本特征重要性的方法。 特征A对训练数据集D的信息增益g(D,A) ,定义为集合D的经验熵H(D)与特征A在给定条件下D的经验条件熵H(D|A)之差,即
$$
g(D,A)=H(D)-H(D|A)
$$
可见信息增益与互信息类似,然后是信息增益比:
$$
g_{R}(D,A = \frac{g(D,A)}{H(D)}
$$
八、参考
- 信息熵 Information Theory
- 《统计自然语言处理第二版》 宗成庆